基础爬虫教程
爬虫:通过一些手段(如Python的requests库)爬取网络中的一些数据
工具:Pycharm(可用其他编辑器平替如vscode),python3.12
一、核心概念
1.1、网络通信相关
1、URL(统一资源定位符)
URL 就是我们常说的"网址",它是网络上每个资源的唯一地址。理解 URL 的组成对爬虫非常重要:
https://www.example.com:443/search?q=python&page=2#result |协议| |域名| |端口| |路径| |查询参数| |锚点|
协议 :http 或 https(加密版本)域名 :服务器地址路径 :服务器上资源的位置查询参数 :向服务器传递的额外信息(爬虫中经常需要构造这部分)
2、HTTP协议
HTTP 是浏览器与服务器之间通信的规则。爬虫本质上就是模拟浏览器向服务器发送 HTTP 请求,然后接收并解析响应 。
3、请求方法
最常见的两种:
GET :从服务器获取数据,参数附在 URL 上(如搜索、翻页)POST :向服务器提交数据,参数放在请求体中(如登录、表单提交)
4、请求头
请求头是随请求一起发送的附加信息,用来描述客户端的身份和能力。爬虫中最常用的字段:
User-Agent :标识客户端类型(浏览器/操作系统),很多网站会根据这个字段判断是否为爬虫Referer :标识请求来源页面Cookie :携带用户登录状态等信息
5、响应
服务器收到请求后返回的内容,主要包括:
组成部分
说明
requests 中的用法
状态码 表示请求结果(200成功,404未找到,403禁止访问,500服务器错误)
response.status_code
响应头 服务器返回的附加信息(如内容类型、编码)
response.headers
响应体 返回的实际内容(HTML、JSON等)
response.text / response.json()
1.2、数据格式相关
1、前端界面的组成
2、网页源代码
3、robots.txt 协议
这是网站根目录下的一个文件(如 https://www.example.com/robots.txt),声明了哪些页面允许爬取、哪些禁止爬取。虽然不具有强制力,但属于行业规范,建议遵守。
二、实战
2.1、百度热搜内容爬取
基础请求、请求头伪装、XPath 定位
1、确认目标网址
2、分析页面结构
3、代码
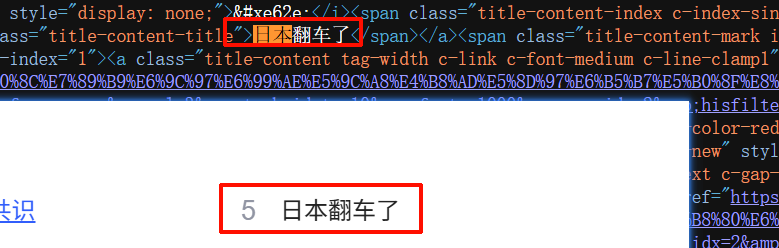
""" 爬取网址:https://www.baidu.com 爬取要求:热搜内容 """ import requests from lxml import etree url = 'https://www.baidu.com' headers = { 'user-agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36' } r = requests.get(url, headers=headers).content.decode('utf-8' ) ret = etree.HTML(r) li_list = ret.xpath('//ul[@class="s-hotsearch-content"]/li' ) for li in li_list: text = li.xpath('.//span[@class="title-content-title"]/text()' )[0 ] print (text)
结果展示:
2.2、哲风壁纸图片爬取
文件下载(图片/视频)、条件判断、文件 IO
1、确认目标网址
2、分析页面结构
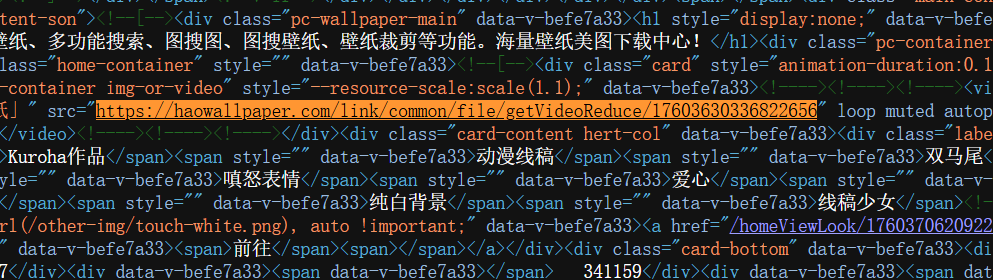
F12快捷键,定位图片位置获取url,再去网页源代码中搜索
发现存在,依旧直接写代码
3、代码
""" os库用来新建文件夹 然后后面有判断语句是用来分辨动态壁纸和静态壁纸,分别写入文件 """ import osimport requestsfrom lxml import etreeif not os.path.exists('wallpaper' ): os.mkdir('wallpaper' ) url = 'https://haowallpaper.com/' r = requests.get(url).content.decode('utf-8' ) ret = etree.HTML(r) div_list = ret.xpath('//div[@class="home-container"]/div' ) n = 1 for div in div_list: wallpaper_url = div.xpath('./div[1]/img/@src' ) print (wallpaper_url) if wallpaper_url == []: wallpaper_url = div.xpath('./div[1]/video/@src' )[0 ] with open (f'wallpaper/{n} .mp4' , 'wb' ) as f: f.write(requests.get(wallpaper_url).content) else : with open (f'wallpaper/{n} .png' , 'wb' ) as f: f.write(requests.get(wallpaper_url[0 ]).content) n += 1
结果展示:
1、确认目标网址
2、分析页面结构
3、代码
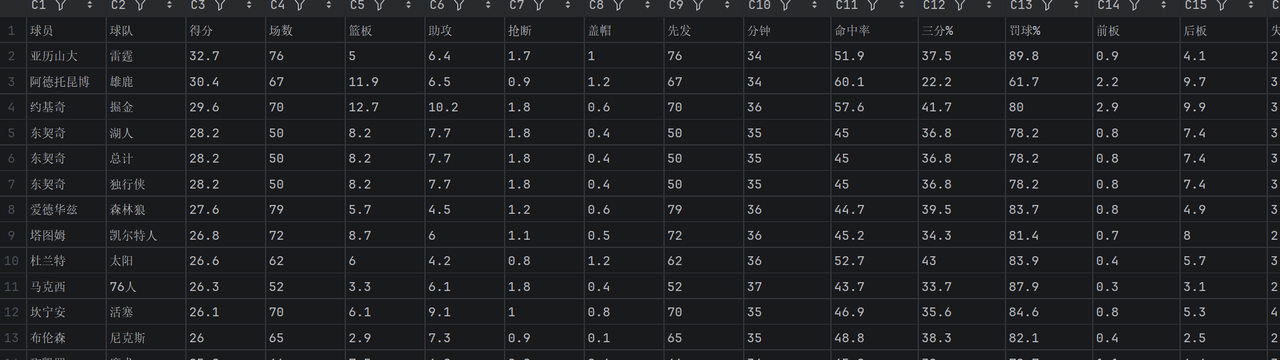
import requestsdef main (): url = "https://data.zhibo8.cc/manage/public/app.php" params = { "_url" : "/nba/player_conditions" , "season" : "2024" , "random" : "0.4268737407850992" } headers = { 'user-agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36' } r = requests.get(url, params=params, headers=headers).json() lst = r['data' ]['data' ]['list' ] with open ('NBA数据.csv' , 'a' , encoding='utf-8' ) as f: f.write('球员,球队,得分,场数,篮板,助攻,抢断,盖帽,先发,分钟,命中率,三分%,罚球%,前板,后板,失误,犯规\n' ) for i in lst: f.write(f'{i['球员' ]} ,{i['球队' ]} ,{i['得分' ]} ,{i['场数' ]} ,{i['篮板' ]} ,{i['助攻' ]} ,{i['抢断' ]} ,{i['盖帽' ]} ,{i['先发' ]} ,{i['分钟' ]} ,{i['命中率' ]} ,{i['三分%' ]} ,{i['罚球%' ]} ,{i['前板' ]} ,{i['后板' ]} ,{i['失误' ]} ,{i['犯规' ]} \n' ) if __name__ == '__main__' : main()
结果展示:
2.4、华为商城数据爬取
POST 请求、请求体构造、Cookie/Token 携带
1、确认目标网址
2、分析页面结构
不是静态的,得抓包;通过翻页获取最新的包
包的分析和页面同理
3、代码
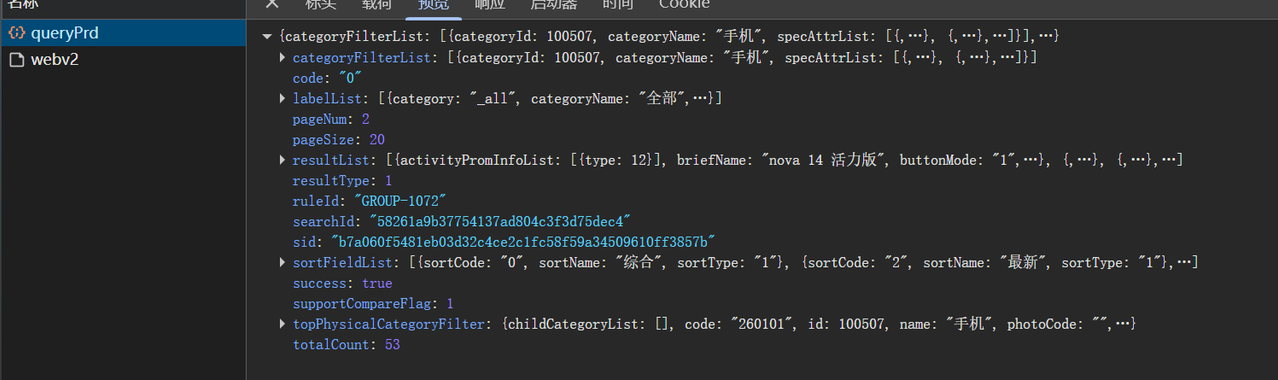
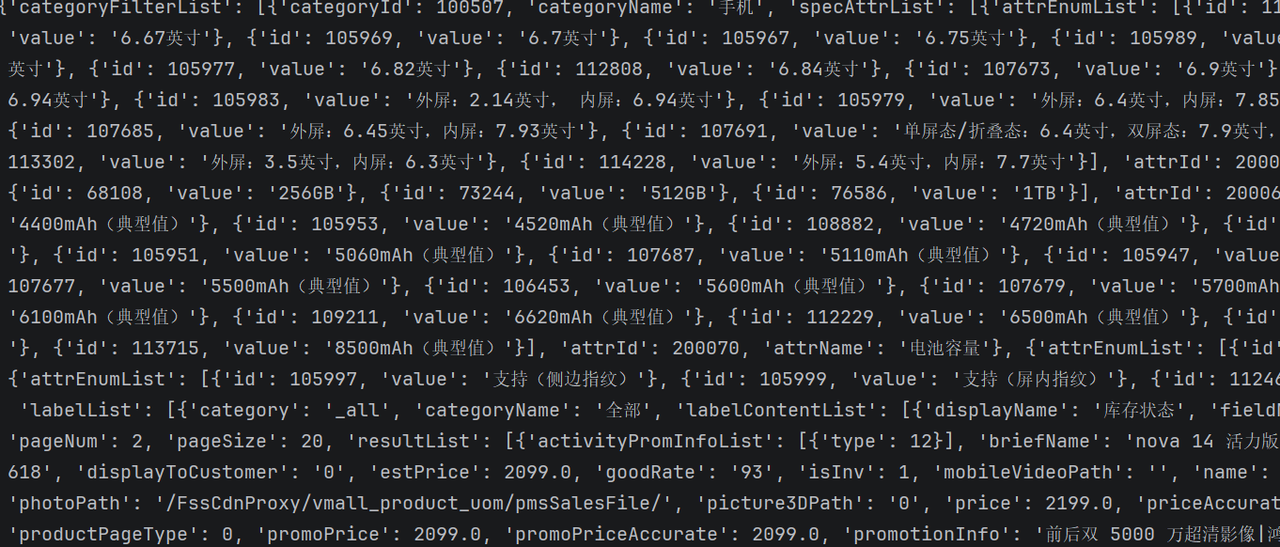
import requestsimport jsonheaders = { "CsrfToken" : "cy6HVAnxwXXJwOOFzHG4LuwwWx9hbDNCc4KX" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36" , "X-E2E-Trace" : "e2eId=page#rn_searchResult#1#10cdbf9e48bcc4911b6e1fadf4121541;spanId=f36a4518a625a618b955fccd0f99189e" , "X-Requested-With" : "XMLHttpRequest" , } cookies = { "perIdb" : "401001097" , "callAB" : "1" , "recommendflag" : "0" , "euid" : "a8d0e83bf467a5a07fafb75460b4e7b6f3686c87b85959fc" , "CSRF-TOKEN" : "cy6HVAnxwXXJwOOFzHG4LuwwWx9hbDNCc4KX" , "HWWAFSESTIME" : "1778822159370" , "HWWAFSESID" : "b69f6346b172e3781a2" , "showAds" : "true" , "deviceid" : "17bc3e4c31f8e3469a387063eb57ee65" , "TID" : "17bc3e4c31f8e3469a387063eb57ee65" , "cartId" : "fbc39de996974e68a164a3f05c0190c9" , "sdevid" : "be101e2963cf2619e7b73b8617b9b4fd6a01292c" , "referer" : "https://www.vmall.com/product/comdetail/index.html?prdId=10086724171251&sbomCode=2601010586509" , "device_data" : "*2k48T5zCyEYUXMJWLUIh4AmmTSM46R9CmDlzTDSk04ltzymmNNMUVNbJcYdsYARE4EyLUIu6QeZZUH1Uj0jTmPx5DEw90RRJI1y2TFJZJZZMPQUI9E10RVUTUmjFZJaNV0xqxmlmmSGU2zTmjjN1NEy095adQZYRJRPd1AF9Bd4Q9oy0rMPJNNUiml0VSj3tum00wmPlZoAnnTj0UQZecSZOyJgE4ZlpUdjylVMPOZU2uu64K3qkDyikV0T348Fcyk1mvLMTNMcZZG1UlQUBQEFoyy1eMTOjWmXjDkSDFmmLJBH9p4NdUnGiDGZRbMQTPZnY4YpRRg9Qj0DUPJZM9Tx4uJmBUiiGzjUjjZZNNwVj3zzLaMLdPZPk4Y1lYk0J5zw1lPcZWSDTVmCDjkmZix41Z3kZabMUYcZF0jecxzPmLi4=" } url = "https://openapi.vmall.com/mcp/v1/search/queryPrd" data = { "tid" : "17bc3e4c31f8e3469a387063eb57ee65" , "sid" : "b7a060f5481eb03d32c4ce2c1fc58f59a34509610ff3857b" , "keyword" : "手机" , "pageNum" : 2 , "pageSize" : 20 , "searchSortField" : 0 , "searchSortType" : "desc" , "screenParams" : "{}" , "personalizeSearch" : "2" , "portal" : "1" , "lang" : "zh-CN" , "country" : "CN" , "searchFlag" : "0" , "brandType" : 0 } data = json.dumps(data, separators=(',' , ':' )) response = requests.post(url, headers=headers, cookies=cookies, data=data) print (response.json())
结果展示:
三、总结
3.1、爬虫的基本流程
确定目标 URL ↓ 分析页面结构(源代码 / F12 / 抓包) ↓ 判断数据类型 ├── 静态页面 → requests 获取 HTML → XPath / BeautifulSoup 解析 └── 动态页面 → 开发者工具抓包 → 找到数据接口 → 请求 API 获取 JSON ↓ 提取目标数据 ↓ 保存数据(txt / csv / 数据库)
3.2、四个案例回顾
案例
数据类型
请求方式
解析方式
核心知识点
百度热搜
静态页面
GET
XPath
基础请求、请求头伪装、XPath 定位
哲风壁纸
静态页面
GET
XPath
文件下载(图片/视频)、条件判断、文件 IO
NBA数据
动态页面(API)
GET
JSON
抓包分析、查询参数构造、JSON 数据处理
华为商城
动态页面(API)
POST
JSON
POST 请求、请求体构造、Cookie/Token 携带
3.3、进阶方向
如果你希望继续深入,可以探索以下方向:
方向
说明
多页爬取 通过循环构造翻页参数,批量爬取多页数据
并发爬取 使用多线程 / 异步(aiohttp)提升爬取速度
数据持久化 将数据存入 MySQL、MongoDB 等数据库
爬虫框架 学习 Scrapy 框架,实现更工程化的爬虫项目
反爬对抗 了解验证码、IP封禁、JS加密等反爬机制及应对方式
动态渲染 使用 Selenium / Playwright 处理需要浏览器渲染的页面
⚠️ 免责声明 :本文所有案例仅用于技术学习与交流目的。在实际使用爬虫时,请务必遵守目标网站的 robots.txt 协议及相关法律法规,合理控制请求频率,不对目标服务器造成过大压力,不将爬取的数据用于商业或非法用途。